Demo
R&D Optimization With Knowledge Graphs
Unlocking hidden insights in your data with knowledge graphs
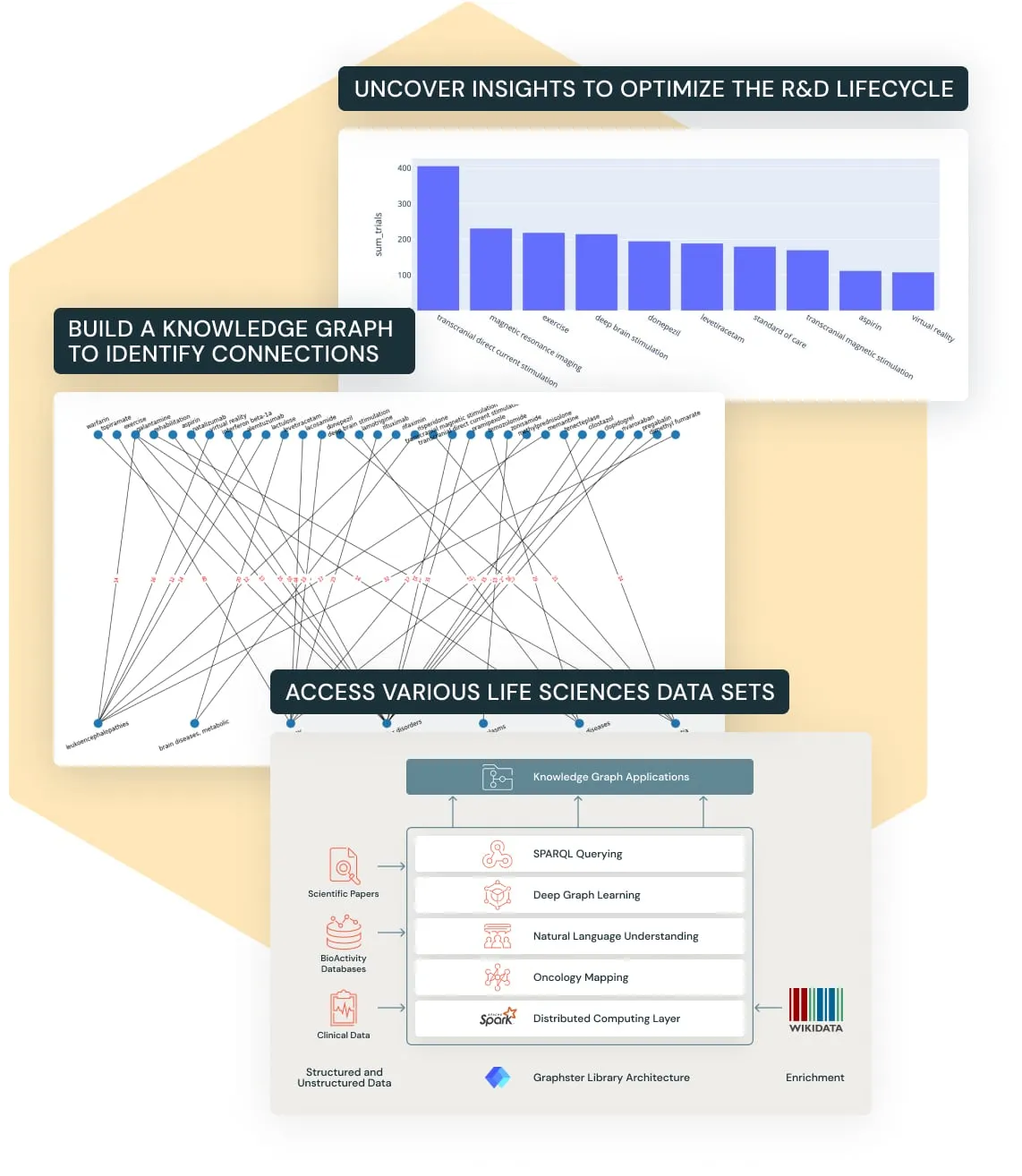
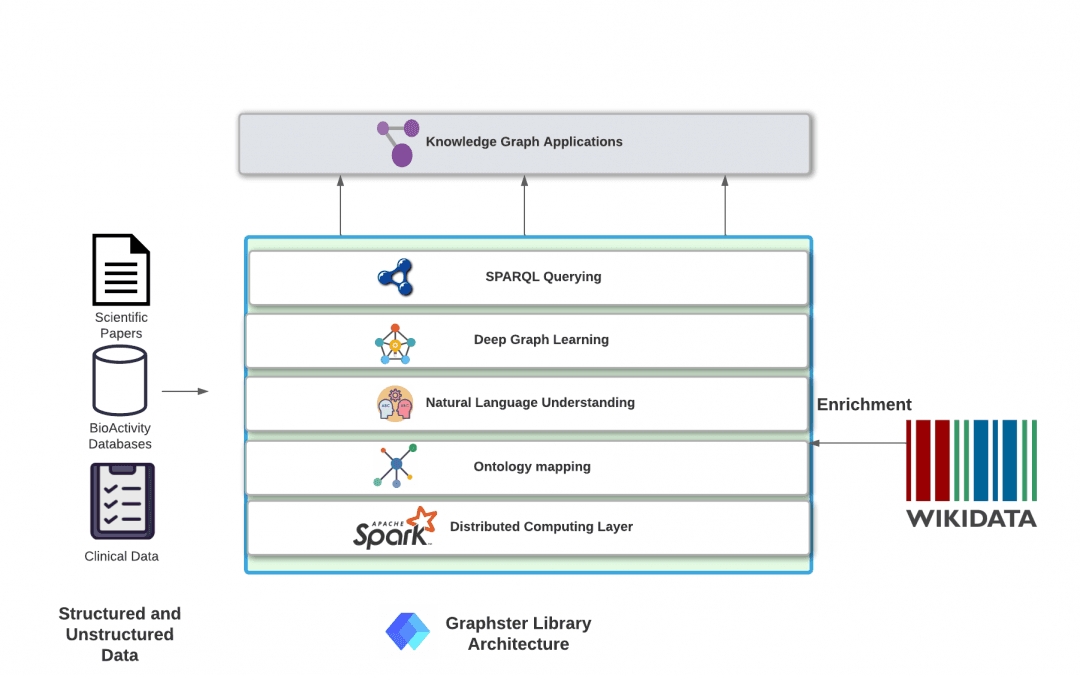
Knowledge graphs combine the semantics, scalability and flexibility of a graph database with the performance and governance of a data lakehouse. With the Databricks Lakehouse for Healthcare and Life Sciences, R&D teams can:
Store and organize all forms of life sciences data in the lakehouse
Synthesize new insights through advanced network analytics and machine learning
Build a knowledge graph with Wisecube to reveal opportunities to improve R&D
Knowledge Graph Construction
Knowledge Graphs are used to represent real-world entities and the relationships between them, and are often built by collecting and integrating data from a variety of sources. An important step in creating a knowledge graph is Data Fusion. Data fusion is the process of combining data from multiple sources into a single, coherent representation. It is often used in situations where there are multiple data sources that are providing information about the same phenomenon, and the goal is to use this information to make more accurate inferences or decisions.
Data fusion can involve a variety of techniques, such as filtering, data cleaning, feature extraction, and machine learning. The specific approach used will depend on the nature of the data and the goals of the fusion process.

This process involves:
Data collection: This involves gathering data from a variety of sources, such as databases, websites, and other online resources.
Data cleaning and preprocessing: This involves cleaning and formatting the data so that it can be integrated into the knowledge graph. This may include tasks such as deduplication, entity resolution, and data standardization.
Data integration: This involves integrating the data into the knowledge graph by creating nodes and edges that represent the entities and relationships in the data. This may also involve mapping data from different sources to a common schema or ontology, which defines the types of entities and relationships that can be represented in the knowledge graph.
Data enrichment: This involves adding additional information to the knowledge graph by integrating data from additional sources or using machine learning algorithms to generate new insights.
Overall, data fusion in the context of knowledge graphs is a process of combining and integrating data from multiple sources in order to create a comprehensive and coherent representation of real-world entities and their relationships.
In this Notebook based demo, we use the graphster library, to perform all the above mentioned steps and build a KG based on integrating clinical trails data with MeSH dataset.